Method
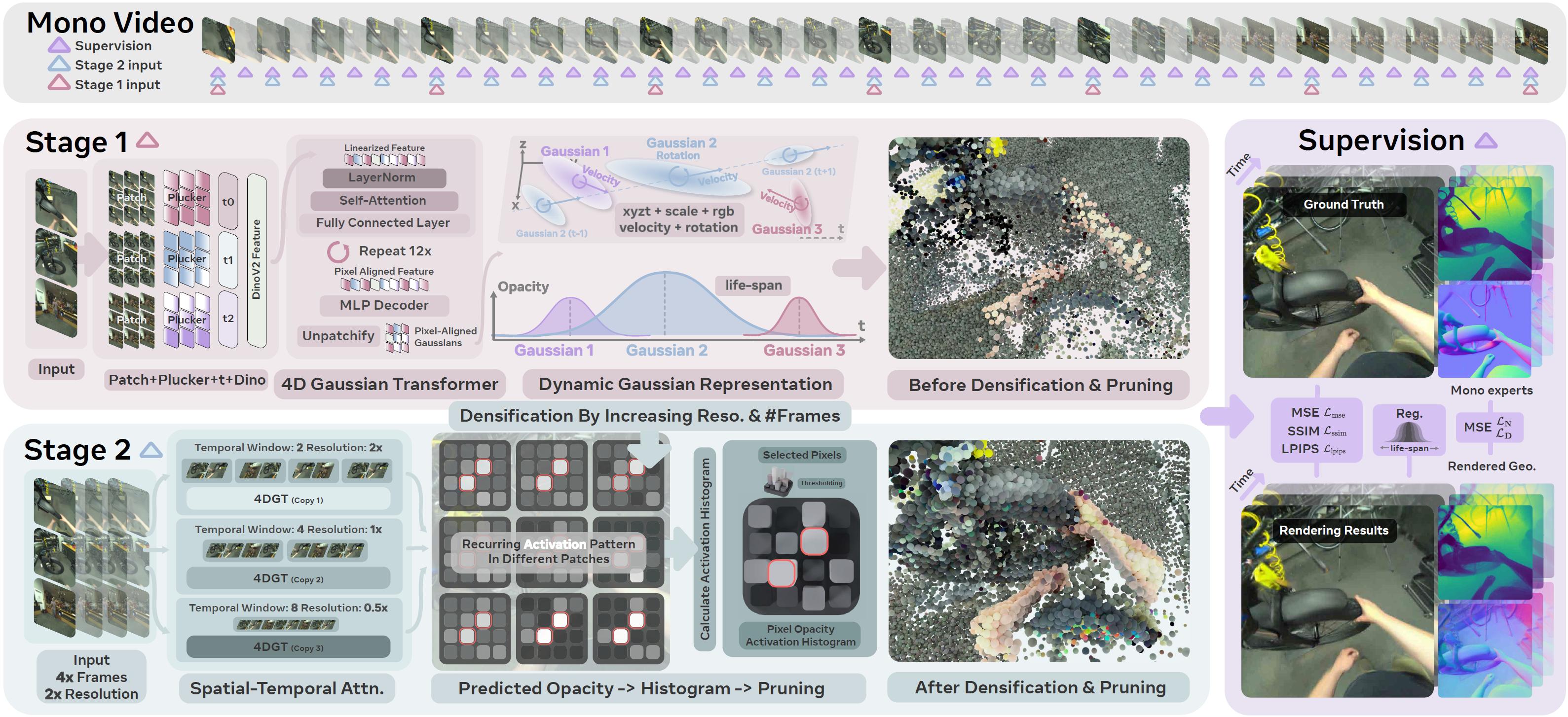
4DGT takes a series of monocular frames with poses as input. During training, we subsample the temporal frames at different granularity and use all images for supervision. We first train 4DGT to predict pixel-aligned Gaussians at coarse resolution in stage one. In stage two training, we pruned a majority of non-activated Gaussians according to the histograms of per-patch activation channels, and densify the Gaussian prediction by increasing the input token samples in both space and time. At inference time, we run the 4DGT network trained after stage two. It can support dense video frames input at high resolution.